Code coverage by
unit-tests (or integration tests - we will not discuss the differences here) is the easiest to add - in many cases much simpler than adding complex end-to-end system tests, and provides good protection against many stupid and easy-to-detect bugs. Here I am only referring to tests that take just a few minutes to run, and can be run as part of the basic build process. No one is saying that it makes the code full-proof against bugs, but no one can argue that having ready tests reduces risks when having to fix a bug or make functionality changes in some code. Code coverage measurement tools are able to provide reports on the portions of code covered by these tests.
Naturally, some developers are adding much more tests on average than others. I don't know where does the lack of writing tests come from - is it out of pressure to meet a deadline, lack of skills or experience, laziness, just not caring, not presenting a sense of ownership ("it's someone else problem"), or any other reason... Also, sometimes, for the same reasons, people tend to remove or disable tests rather than fixing them - either at the same moment, or shortly after committing the code that broke these tests. This, inevitably, leads to having the coverage percentage going down.
Quite for some time, I have been thinking about a method that will hopefully continuously increase code coverage by tests. I am sure that I am not inventing anything new here, but so far I did not encounter any teams that are actually using such a method, and anyway - this is a great way to get feedback on ideas :)
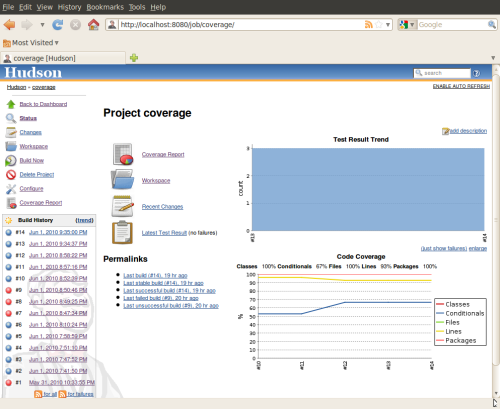
Continuous integration tools, such as
Jenkings (former
Hudson), have appropriate plugins for displaying code coverage results over time (see a
screenshot example) . Moreover, these tools can be configured to mark the build as failed, if the code coverage percentage for the current revision is lower than for the previous revision.
This way, if someone commits code with lower coverage percentage than the current percentage in the trunk (by not writing enough tests for the new/fixed code, or disabling existing tests), the build will be broken, just as if this person committed code that doesn't compile, or caused any tests to fail, and it will require a similar response (either provide a quick fix, or revert the commit).
For example, let's say we start the process at the current state, and we have 40% code coverage by such measurable automatic tests. The above process ensures that we will never go below this coverage percentage. But how do we go up ? Well, statistically, some of the developers will have much higher code coverage on their code, thus moving the overall average higher. This will automatically set a new, higher, goal from that moment on.
But what if adding more tests for some specific change is highly difficult and is not cost effective ?
Well, my suggestion is that in this case, since the developers do not want to break the build, they much compensate by adding tests for different (possibly even unrelated) code, merely so that the overall coverage won't go down. Over time, such an "escape route" will ensure that at least all the easy-to-test areas in code will be well covered.
Of course, reaching 100% coverage is virtually impossible, and also at most times non cost-effective. So we can set a lower percentage threshold (75-85%) for coverage, and once reached, just make sure that the coverage does not go below this threshold. In addition, at all times the code that still does not have code coverage, will be the code for which writing tests is the least cost-effective, or that is better to be covered by more complex system tests, that cannot be run as part of the continuous integration system measurement tools.
I am sure that such an approach is a bit controversial, so I would be happy to hear feedbacks and suggestions how to improve such a method.
My main concern for adoption of such a method is the social concern - how well will it be perceived by the developers, will the developers that indeed lowered the coverage percentage take the responsibility to fix it quickly, or will there be just a continuously "red" continuous integration system status, that no one cares about...
I must say that I still do not have any actual experience or results for this method. Hopefully we will be able to try it in our group in the next months.
I will update on any insights and conclusions as we go...




{kind=link}